Share this
![]() Richard Verhoeff
on Apr 1, 2022 12:16
| Updated: May 15, 2026 12:36
Richard Verhoeff
on Apr 1, 2022 12:16
| Updated: May 15, 2026 12:36

Every organization wants to be data-driven because data is a powerful asset that helps drive smarter decision-making. But to use this power effectively, you need a well-designed data infrastructure, and building a customer data model is one of the five foundational elements of a modern data stack. Alongside data ingestion, visualization, intelligence application, and activation, customer data modelling helps democratize analytics across your organization.
Customer Data Management is another critical aspect of leveraging data effectively to ensure it is properly managed and utilized, as explained here.
The Foundations of a Modern Data Stack
Creating a customer data model is the second key foundation after data ingestion. Once you've ingested customer data, whether from your data warehouse or lakehouse, the next step is to shape this data into useful forms for your teams and systems. This involves designing a structure that can support data-driven decision-making across different business units. A solid architectural design is key to long-term success, as it ensures the data is organized into actionable entities that fit your specific business use cases.
Two key components are essential to creating an effective customer data model:
-
Identity Resolution: Identifying the same users across different data sources.
-
Master Data Model: Creating a clean, unified view of your customers, enriched with facts and dimensions.
A good approach is to begin with incremental development and rapid iteration. Establish business objects that facilitate growth, such as customer profiles, transactions, and events.
Identity resolution
This first step is building out the identity graph of clients and users in a global identifier linking (also called "stitching" by many) all customer interactions with your channels and applications.
The 3 key steps for SQL based simple identity resolution in your Data Warehouse:
Identify match keys
This is to decide which fields or columns you’ll use to determine which individuals or subsidiary companies are the same within and across sources. A typical example of match keys might be an email address and last name.
Aggregate customer records
The second step is creating a source lookup table with all the customer records from your source tables.
Match and assign a Global Customer ID
The final step is to take records that have the same (or, in some cases, similar) match keys and generate a unique customer identifier for that matching group of customer records at your company level. I call this a Customer ID. The generated customer ID can be used to link the customer sources together going forward. This blog about first-party data strategy describes what this looks like in practice.
As you add more sources, you can start rolling them into the same process by setting the correct rules and precedence for the source.
Here's an ERD for what the process can look like in a sample Implementation:
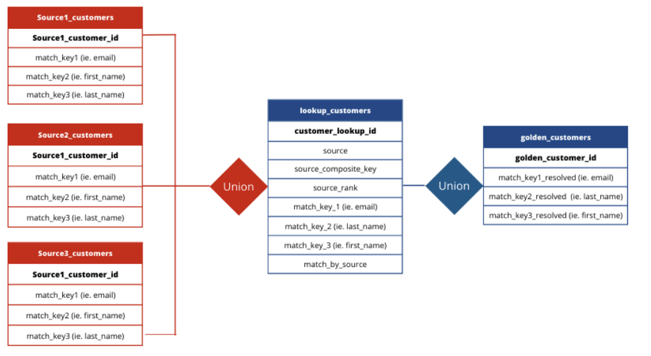
Creating master data models
By creating your first customer view, you’ve solved the first identity problem. Next, you'll need to get your data pipelines or ETL processes in place to build your master models that will drive analytics.
To drive quick value, start with a “Customer→Transaction →event ” framework. This framework creates the three key objects from your source data.
The image below shows what this type of modelling looks like.
Customers: Table of your customers with the ability to quickly add new fields add new fields
Transactions: Join key from customers' table to their transaction history, including product returns for a retailer for example
Events: Any event you track from each customer
If your company is a marketplace or has different business identities, you can change these master data models to follow what makes sense. For example, you might have tables for both sellers and buyers as different entities for a double-sided marketplace. For a B2B business, you might have separate accounts and contact entities.
-png.png)
Tools for Data Ingestion and Transformation
There are several ways to ingest and transform data into your data warehouse. In most cases, analytics teams adopt an open-source solution. Over the past few years, open-source tools for creating the modern customer data stack / CDP have made managing and maintaining data easier while significantly reducing costs.
Most used in open source are Airflow and Beam. Airflow shines in data orchestration and pipeline dependency management, while Beam is a unified tool for building big data pipelines.
Airflow is widely used for workflow orchestration to run data pipelines or machine learning models. At Crystalloids, we deploy Airflow and Beam with Cloud Composer and Cloud Dataflow.
-
Airflow: Ideal for managing data pipeline dependencies and orchestration.
-
Beam: Suitable for building unified, large-scale data processing pipelines.
Both Airflow and Beam can be deployed with managed services like Google Cloud Composer and Cloud Dataflow or on AWS. Other alternatives to Airflow include Prefect, Dagster, and Kubeflow.
If you have the structured data sitting in your data warehouse, you can also write all your transformations in SQL. You may wonder how it is possible to manage all these transformations when they scale up to the hundreds. Saving hundreds of SQL queries in some folders is not an easy thing to maintain.
What about if I want to update one of those transformations? Or roll back to a previous version of one of my SQL scripts? If you are already at this stage, then DBT (Data Build Tool) will be your friend. dbt will help you manage all of this complexity just by integrating some practices like documentation, transformation/model lineage (i.e. which transformation goes first), data testing (i.e. weird to have transactions with negative values), and some excellent version control with Git to make sure that you have everything in one place and you can track versioning.
Implementing CI/CD in Data Pipelines
Once you've cleaned and transformed your data, managing changes is crucial. We recommend using a CI/CD workflow to ensure that all adjustments to your models are properly vetted before deployment.
For instance, the cleaned model can be stored as views in BigQuery and versioned using Cloud Source Repositories or Bitbucket. From there, tools like Google Cloud Build help guide these changes through a controlled development, testing, acceptance, and production (DTAP) process.
Conclusion
A customer data model is one of the five foundations for creating a modern data stack. If you need assistance creating modelling elements as described in this blog, we are here to help.



%20(1).png?width=75&height=75&name=Contact%20Services%20(800%20x%20800%20px)%20(1).png)
