Share this
![]() Richard Verhoeff
on Nov 16, 2021 16:13
| Updated: Jan 22, 2026 15:41
Richard Verhoeff
on Nov 16, 2021 16:13
| Updated: Jan 22, 2026 15:41
%20(24)-1.jpg?width=690&height=388&name=Blog%20Format%20(1120%20%C3%97%20630px)%20(24)-1.jpg)
In the world of marketing analytics, where valuable insights come from merging data from various sources, Data Vault Modeling stands out.
Many companies transform data through an ETL (Extract, Transform and Load) process and store data in Data Warehouses for further analysis. There are multiple ways to manage data in such a way that they support data and insight-driven decision-making.
One of the most recent data management approaches is Data Vault Modeling (DVM). For data engineers, this data model offers a structured framework to design, implement, and maintain data architectures that are agile and resilient. Data scientists, on the other hand, benefit from the robust foundation it provides for exploring, analyzing, and extracting valuable insights from complex datasets.
This method offers a highly scalable solution for the long-term historical storage of data originating from various operational systems. So, what challenges does data vault method aim to address, and in what scenarios does data vault architecture emerge as the optimal choice? Let's delve deeper into the data vault methodology to explore how it transforms data into a valuable asset for decision-makers.
What problem does Data Vault Modeling solve?
Before we look deeper into this question, first, let’s have a look at other common data warehouse architectures.
A classical approach to managing data is the dimensional design approach. This architecture aims at processing data and delivering results quickly to end-users. However, it may struggle with handling new data efficiently, and creating data marts often involves significant effort to reshape the data model. Data vault modelling, introduced by Dan Linstedt, offers an alternative that addresses these issues, making it a compelling choice in the realm of data warehousing and data science.
Dimensional modeling (DM)
The purpose of DM is to optimize the database for faster retrieval of data. Dimensional data models deal with Dimension and Fact tables.
Let’s say, in an E-commerce use case where a company, with big data, has multiple products and stores, Dimension tables can be Product, Customer, Store etc. Dimensions have a unique identifier and other attributes.
For the dimension Customer, the unique identifier, also called the primary key could be customer_id and the attributes could be name, surname, email, address etc. Facts tables are tables like order details, metrics and transactions from different business processes which have a foreign key relationship with one or more Dimension tables. An example of a Fact in this use case would be the order table.
A star schema is then used to create an aggregated view or report of a business requirement. An example of a star schema applied to the E-commerce use case can be seen below.
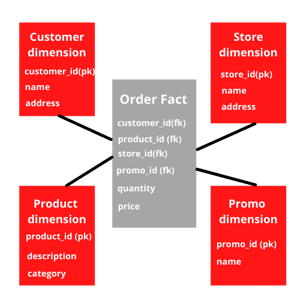
Drawbacks of Dimensional modeling
The problem with DM is that when the business is growing, this way of modelling oftentimes isn’t flexible and agile enough. The problem starts to arise when, for example, a business requires information on a different grain.
For example, overview of sales made in a specific city. You can add an extra attribute to the existing Fact table. Then the risk of data inconsistency starts to arise, or you might lose your history. Another option would be to create a new Fact table with almost the same information but on a different grain. It adds complexity to the model and leads to the fact that a star schema is very much oriented on a particular view, which makes it less flexible.
Therefore DM is not always responsive to changing business needs. If you are looking for a more flexible solution, this is where data vault architecture comes in.
Data Vault Modeling
DVM serves as the backbone of a data warehouse, providing a strategic approach to data integration. This modern data vault methodology is based on flexible modeling patterns that harmoniously integrate raw data based on business keys. The data model is much more immune to changes in business needs because of separating structural information from descriptive attributes.
One key advantage lies in its ability to enable parallel loading, allowing large implementations to seamlessly scale out without necessitating a model overhaul. In essence, DVM contains data sources from various channels, making it a versatile and adaptable solution.
When it comes to managing and harnessing data effectively, organizations can benefit greatly from incorporating a customer data platform (CDP). A CDP excels in integrating data from diverse sources while ensuring data quality and consistency. By combining the adaptability and scalability of DVM with a CDP, organizations can create a robust foundation for data-driven decision-making.
A Data Vault approach consists of three essential components: Hubs, Satellites, and Links. Together, these elements form a comprehensive grammar that articulates the intricacies of the business under analysis.
A Data Vault design consists of:
- Hubs
- Satellites
- Links.
Hubs
The Hub is an entity that has significance to the business. It only holds a unique identifier that can directly relate to the business. So in our example hubs would be Product, Customer, Store and Promo with their unique identifiers product_id and customer_id.

Links
Links show that two hubs are related. They are primary/foreign key relationships and describe a unique relationship between two hubs.
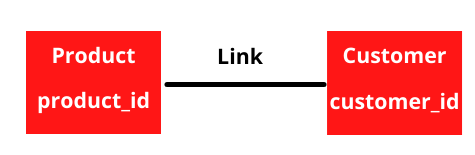 Satellites
Satellites
Satellites record “point in time” values. You can compare them with the attributes in a dimension table. They connect to Hub or Link tables, but not to other satellites. Satellites are associated with only one Hub. They hold the history as fresh records. Each time there is a change in values a new Satellite record is stored with a timestamp.
This means that there are no deletions or updates in a data vault, only inserts. It allows an answer to the question: “What did we know when?”
.png?width=500&name=Product%20(5).png) A simplified overview of a data vault model looks as follows:
A simplified overview of a data vault model looks as follows:
.png?width=1000&name=Product%20(4).png)
Use cases for Data Vault (DV)
Now, let's explore how a Data Vault can seamlessly adapt to evolving business needs. Imagine a scenario where a Store suddenly requires tax details, data that may originate from another system.
In response, a DV can effortlessly accommodate this change by creating an additional satellite to hold the tax details, all without disrupting the existing data structure. This flexibility ensures scalability, adaptability, and data consistency, aligning perfectly with data warehouse practices.
This hybrid database modelling technique takes the strengths of both data warehouse and data lake approaches. However, it’s not suitable for every type of reporting or any type of use case.
Here are five use cases of Data Vault, highlighting its role as the best practice for enabling efficient data management:
-
Dynamic Business Environments: In rapidly evolving industries, traditional data management struggles to keep pace with changing structures. DV excels in such dynamic environments, allowing organizations to adapt seamlessly and accommodate evolving data needs.
-
Historical Data Preservation: When historical data is crucial, DV stands out. It tracks changes meticulously by incorporating load time as part of the primary key, creating a rich historical record. This makes it an ideal choice for businesses that require comprehensive historical data for analysis and compliance.
-
Scalable Solutions: Building a Data Vault enables data scalability without the need for frequent model redesigns. As data volumes grow, DV can efficiently handles the load, making it a best practice for organizations looking to expand their data capabilities.
-
Data Integration Across Diverse Sources: DV serves as a robust solution for integrating data from various sources, including structured and unstructured data, ensuring consistency and quality. It's particularly valuable in scenarios where data originates from disparate systems.
-
Efficient Data Warehousing: DV enables the efficient loading of data into data warehouses. By allowing many tables to be loaded in parallel, it optimizes data pipelines, streamlining the process of ingesting, storing, and accessing data, making it a best practice for data warehousing.
In these diverse use cases, DV proves to be a versatile and effective approach for organizations seeking to enhance their data management practices.
When would you not use a Data Vault?
When considering the use of DV, it's essential to recognize scenarios where it may not be the optimal choice for your data warehouse with data vault:
-
Direct Reporting Needs: If your primary objective is to load data directly into a reporting tool for immediate analysis, DV might not align with your requirements. Its structure, characterized by numerous joins, can impede performance. To optimize reporting capabilities, a DV typically necessitates an intermediary dimensional model or a dedicated reporting layer to enhance data access speed.
-
Single Source or Static Data: DV benefits become evident when dealing with multiple sources and dynamic data environments. However, if your data landscape involves only a single source system or static data with minimal changes, the complexities of a DV may outweigh its advantages. In such cases, a more straightforward DM could prove to be a better fit, requiring less data manipulation and offering a more streamlined view of data.
Conclusion
In conclusion, DVM offers a flexible approach for data management, making it a best practice for enterprise data warehousing. DVM efficiently integrates raw data while staying adaptable to changes in business needs. It handles scalable data effectively and maintains a comprehensive view of data with its structured architecture of Hubs, Satellites, and Links.
However, it may not be the best choice for direct reporting needs or in situations with single-source or unchanging data. In the dynamic world of data mining and data-driven decisions, understanding when to use DVM and when to consider other options is crucial for organizations aiming to optimize their data assets.
Customer Case: Rituals Cosmetics
Data Platform to Improve Data Access and Analysis



%20(1).png?width=75&height=75&name=Contact%20Services%20(800%20x%20800%20px)%20(1).png)
