Share this
by Nande Konst on Jan 17, 2022 10:18:58 AM

Choosing suitable storage options is essential to yielding optimal results. Selecting the right storage option enhances the performance of your services pipeline, but it also helps you set up a cost-effective data storage solution. By keeping in mind some of the basic principles of storage and acquiring adequate knowledge, the running costs of the backend system can be turned into a cost-efficient system. At Crystalloids, we help you choose the proper data storage solution for your use case. In this blog, I will cover the various storage options on the Google Cloud Platform. I will explain what the options are and in what situation what storage should be implemented.
Google Cloud Storage
Google Cloud Storage is Google’s object storage system. I assume that you have heard about object storage before, but if you didn’t, in straightforward terms, it means as much as this: you tell your storage system, keep this arbitrary sequence of bytes and let me address it with a unique key. In Google Cloud Storage, these special keys are in the form of a URL, which means that it interacts well with web technologies. Google Cloud Storage can be advantageous when documents and reports are shared frequently between multiple departments of an organization. It helps reduce the number of attachments that need to be sent over email.
Cloud Spanner
Cloud Spanner is Google’s distributed relational database service running on the Google Cloud Platform. It is designed to provide both availability and consistency. It combines relational semantics (schemas, ACID transactions, SQL) with horizontal scaling in all regions without latency. Cloud Spanner has some significant advantages when handling massive amounts of data with a high level of consistency, and a large amount of data, around +100.000 reads/writes per second. With a traditional SQL database, there are two things you can do if you need more capacity. You either scale up, which means you have to invest in more servers. You can also choose to scale out, which is cumbersome because you have to add a middleware layer which might be challenging to maintain. With Cloud Spanner, you enjoy the benefits of horizontal scaling.
Use cases for Cloud Spanner
Google Cloud Spanner has many advanced features for analytical processing, such as improved query performance, partitioning indexes, and data loading. This is why an RDBMS like Cloud Spanner is a good choice for any global analytical processing system that runs in the cloud. Another use case for Cloud Spanner is the case where data can only be stored within geographic regions. Some countries have legislation that requires companies to store and process data within their geographical boundaries. Spanner is a great choice for this scenario since its resources are divided across different regions worldwide. The last use case I want to discuss is the use of Spanner in the financial sector. This industry has all the requirements that Spanner can fulfill. Communications among banks must always run flawlessly. Applications such as payment gateways and online banking handle hundreds of millions of daily transactions. Managing these kinds of applications in the past meant repeatedly re-architecting database infrastructure. Nowadays, Google Cloud Spanner handles this with ease.
Cloud SQL
Cloud SQL is a database system that allows you to set up, manage and maintain relational databases on the Google Cloud Platform. You can use MySQL, PostgreSQL, and SQL Server. Cloud SQL offers easy-to-use migration tools that you can use to migrate your database from on-premise or other cloud environments. The advantage is that you don’t need migration servers to provision or manage.
Hybrid deployment on Cloud SQL
One of the advantages of Cloud SQL is that you can use different deployment models. Hybrid deployments, for instance, are helpful when you have an application in the cloud that needs to access an on-premise database or vice versa if you are performing marketing analytics with on-premise systems that need to access customer data hosted in the cloud.
The following image illustrates a hybrid setup with Google Cloud and on-premise systems.
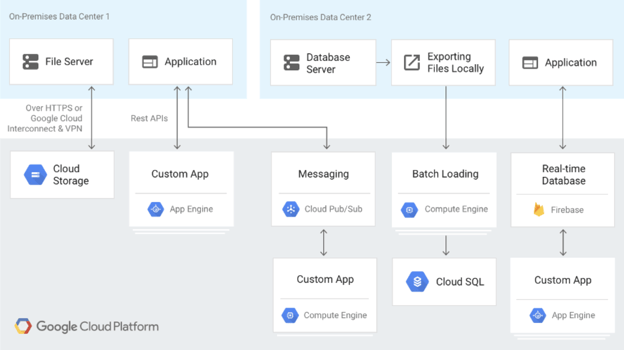
Multicloud deployment
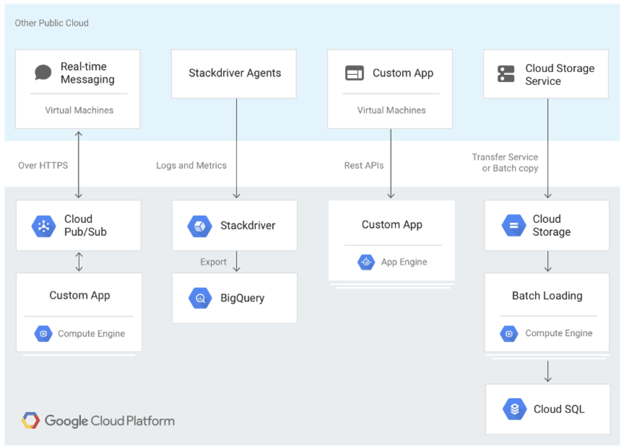
With a multi-cloud deployment, you can combine databases deployed on Google Cloud with databases on other cloud providers. This helps you distribute your database more effectively and take advantage of a more comprehensive array of cloud features.
This image shows a multi-cloud setup:
Cloud BigTable
Let’s say you provide software that gives personalized recommendations based on machine learning. In this case, you need large amounts of data to fuel your machine learning algorithms. You need a database that scales easily and allows for large numbers of reads and writes per second at low latency. This is precisely where Cloud BigTable can help. BigTable is a fully managed NoSQL (key-value pair) storage that supports large analytical and operational workloads and can process millions of requests per second. An advantage of BigTable is that it integrates easily with popular big data tools such as Hadoop, Spark, BigQuery, and Beam. In BigTable, at the intersection of each row and column combination, you can have multiple cells, with each cell representing a different version of the data at a given timestamp. This makes BigTable great for time series analysis.
BigQuery
Data is only helpful if you have a way to analyze it. BigQuery was designed to do just that with massive amounts of data. BigQuery is a fully managed and serverless data warehouse that helps to avoid the data silo problem. This problem occurs when you have individual teams handling individual data marts. This results in data analysis friction across teams.
BigQuery consists of three parts: storage, ingestion, and querying, where data is stored in a structured table. This means you can use SQL for querying and data analysis. Big Query is integrated with the rest of the Google Cloud Platform, which means you can import data from other services like Cloud Storage. Big Query is a beneficial solution when you want to combine data from different sources which need to be analyzed.
Cloud Datastore
If you build web applications where you don’t need heavy SQL functionalities like multiple JOINS, Cloud Datastore might be your best choice. Datastore is a highly scalable NoSQL schemaless database. It automatically handles replication, sharding, and scales to handle your applications’ load. With Datastore, you can create indexes on multiple columns of a table. It also provides ACID transactions, indexes, and SQL-like querying.
Cloud Firestore
Cloud Firestore is another NoSQL storage option that the Google Cloud Platform offers. It’s focused on web and mobile apps and lets you easily store sync and query data. Web and mobile apps can access Cloud Firestore directly through native SDKs for Node.js, Python, Java, C++, and Go.
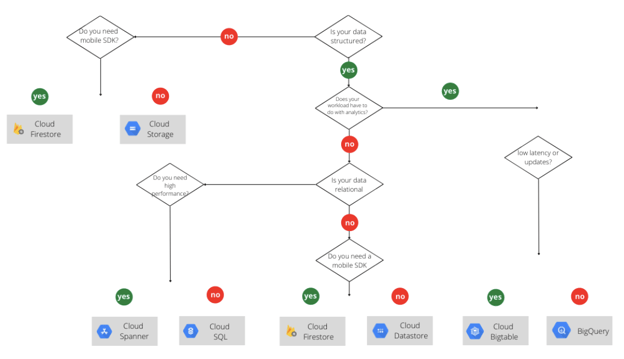
So, how to pick the right storage?
Which storage option is right for you depends on your data's nature and use case. In brief, you should think about the following questions:
- Is my data structured or unstructured?
- Is my data relational?
- Do I need mobile SDKs?
- Does my use case have anything to do with analytics?
To make things easier for you, we made this flowchart so you will have a clear overview of the possibilities, depending on the nature of your data.
If you are considering migrating to the Google Cloud Platform but aren’t sure where to start, drop us a note. Crystalloids is a Google Cloud Premier Partner with Data warehouse modernization as one of its specializations. We use Google BigQuery to streamline the Data Warehouse Modernization path. If you would like to know more, please drop us a line.
ABOUT CRYSTALLOIDS
Crystalloids helps companies improve their customer experiences and build marketing technology. Founded in 2006 in the Netherlands, Crystalloids creates crystal-clear solutions that turn customer data into information and knowledge into wisdom. As a leading Google Cloud Partner, Crystalloids combines experience in software development, data science, and marketing, making them one of a kind IT company. Using the Agile approach, Crystalloids ensures that use cases show immediate value to their clients and free their time to focus on decision making and less on programming.


